...
In JEMH 2.7.3 we address this area by migrating the CSV expressions from the Profile level down into Project Mappings, which is how JEMH is evolving (closer to the sister product JEMHC view).
What | Where is it now | Notes |
|---|---|---|
Profile Subject Cleanups | Re-named Global Subject Cleanups | Values are entered as regular expressions, separated by commas (CSV). |
Profile Body Cleanups | Re-named Global Body Cleanups | Values are entered as regular expressions, separated by commas (CSV). |
Body Cleanup Order | Setting removed | Global cleanups at the profile level are applied before directives processing. Project Mapping cleanups are applied after directive processing. |
Body Delimiters | Migrated into
| The pre-migrated body delimiter expressions could be prefixed with a \n expression for newline, which limited the number of matches to the number of lines in the email, this reduced regexp matching for large emails from billions to a few K (impact of this was processing time). As part of the migration, each historic CSV regexp value was evaluated, and if it started with a \n, had it removed. The reason for this is that ALL Body Delimiters are now prefixed the \n at evaluation time, ensuring that the evaluations are as safe and optimal as possible as well as minimizing the repetitive nature during entry. |
Profile Imports
Old Profiles can be imported into 2.7.3, which will also migrate Body Delimiters from the Profile level to the Default Project Mapping.
Project Mappings
| Note |
|---|
Expressions entered within the Default Project Mapping will be inherited and used by the other Project Mappings within that Profile |
JEMH configuration is being migrated to project-scoped Project Mappings that permit customization within a Profile. There is a Default Project Mapping, which contains no rules, and is used when no other Project Mapping rule matched. The Default Project Mapping can have Cleanup and Delimiter expressions defined that are used by any other Project Mapping as well as having their own.
Type | Subject Cleanup | Body Cleanup | Body Delimiter | Aggregates |
|---|---|---|---|---|
Profile |
|
|
| n/a |
Default Project Mapping |
|
|
| From Profile |
Mapped Project Mapping X |
|
|
| From Default |
Mapped Project Mapping Y |
|
|
| From Default |
Regex 101
Remember that symbols mean something, the dot character ( . ) means match on any character. The star character ( * ) means match on any number of the previous characters. Ranges can be used, eg \[0-9]* means any length of numbers, \[A-Z]+ means 1 or more ALPHA chars, \[0-9A-Za-z]+ means 1 or more ALPHANUM chars. In subjects, there is one line, in body, . matches ALL (full content).
...
Setting the Profile Default Project Mapping Cleanups
| Note |
|---|
Expressions entered within the Default Project Mapping will be inherited and used by the other Project Mappings within that Profile |
With the Test Case set, access the Pre-Processing tab shown below, and click Add in the Subject section:
...
When we run the Test Case with and without the Body Delimiter we can see the differences more clearly.
With expression | Without expression |
|---|---|
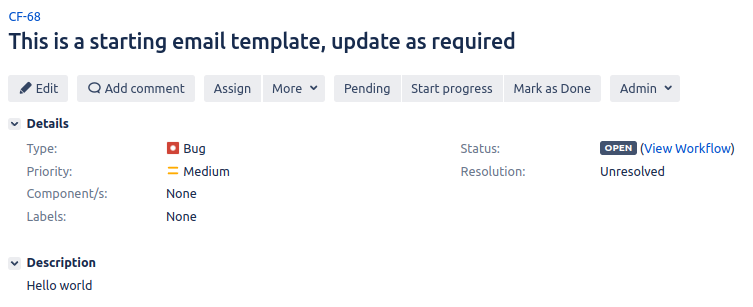 | 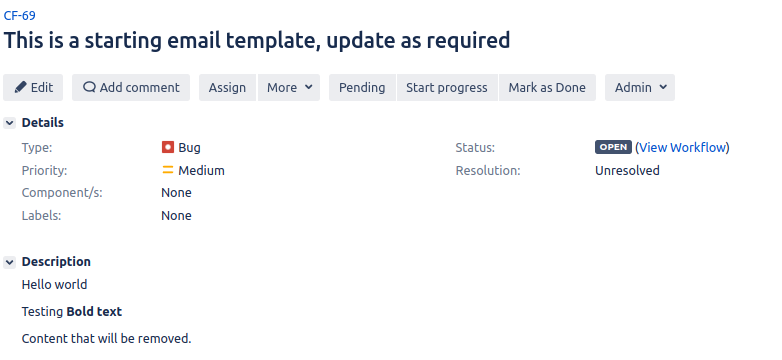 |
Using Body Delimiter with styled text
...
The rendered content will make the text use the formatting that is defined and will remove the Wiki Markup tags from the text. The non rendered content will have the Wiki Markup tags within the text. Below is an example showing the difference between the rendered and non rendered content.
Rendered content | non rendered text content |
|---|---|
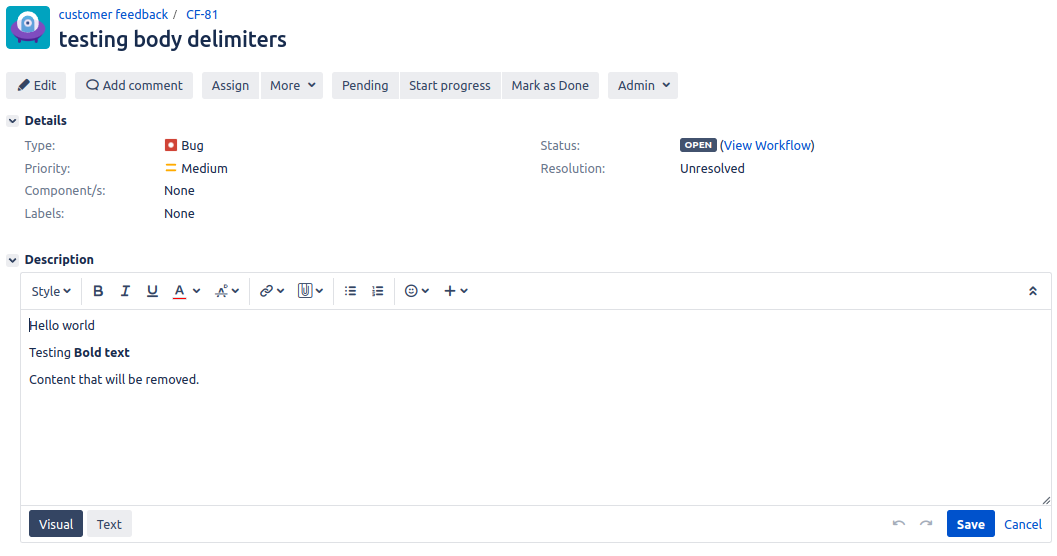 |  |
Using Special characters in a regex expression
...
Commonly used special characters
Special character | Function |
|---|---|
. | This will match any single character other than a newline |
* | This matches zero or more consecutive characters. For example (/ba*) will match “ba” and “baaa” as the expression will match more than one “a” characters. |
\ | Escape following special character. This will allow special characters to be matched within the email. For example if you are looking for “[abc]” the regex will have to be \[abc\] as this will mean that the regex will also look for “[ ]” as a character. |
( ) | Used to define a capture group within a regex. |
[ ] | This is used to define which Character sets you want to capture. For example ([a-z]) will capture all characters that are a lower case alphabetical character. |
Example of using Special characters
...
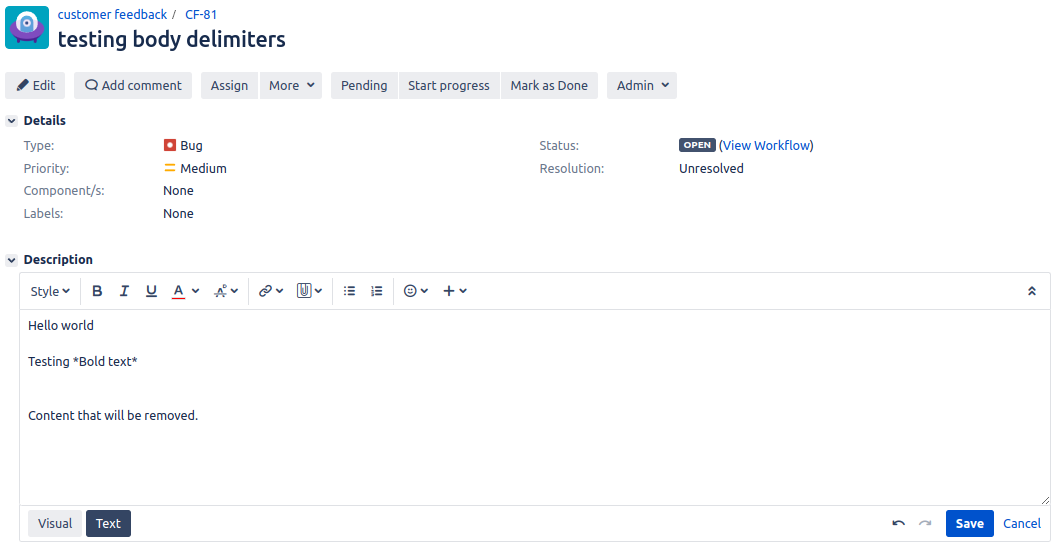
After running the Test Case we can see that the content is removed from the middle of the second line as this is where the Regex found a match for *Bold text*.
Without Regex | With Regex |
|---|---|
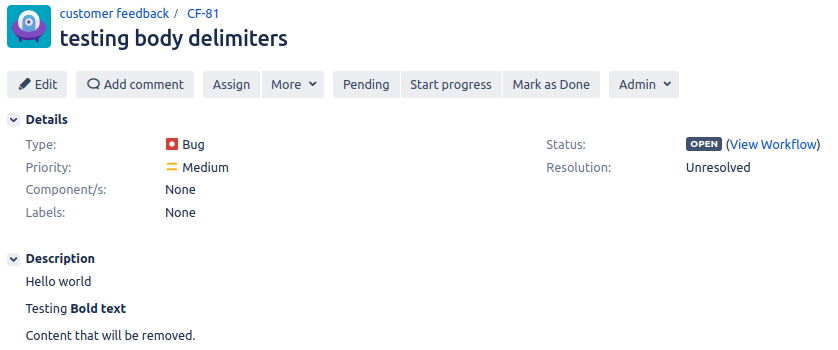 | 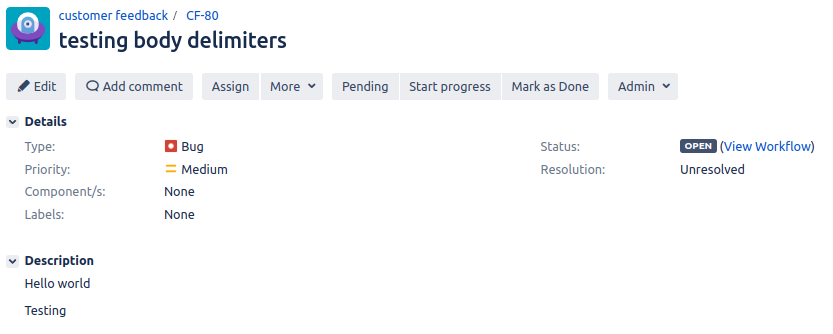 |
Removing ‘Null’ characters
...