Since
Available since JEMH 2.7.3
Introduction
History
JEMH has always had Cleanup Expressions (used to remove content from message subjects and body) and Body Delimiter Expressions (used to chop signature text as well as reply-to content). It worked, but it had two main usability problems:
Fields involved were comma separated regular expressions, which was complicated to manage and had side effects on usability (like matching comma literal characters)
Expressions were global within the Profile, so applied to all issues regardless
Understanding what the impact of a change would be required (a) saving the profile (b) running a test case to (c) view created issue and see the result
What has changed
In JEMH 2.7.3 we address this area by migrating the CSV expressions from the Profile level down into Project Mappings, which is how JEMH is evolving (closer to the sister product JEMHC view).
What | Where is it now | Notes |
|---|---|---|
Profile Subject Cleanups | Re-named Global Subject Cleanups | Values are entered as regular expressions, separated by commas (CSV). |
Profile Body Cleanups | Re-named Global Body Cleanups | Values are entered as regular expressions, separated by commas (CSV). |
Body Cleanup Order | Setting removed | Global cleanups at the profile level are applied before directives processing. Project Mapping cleanups are applied after directive processing. |
Body Delimiters | Migrated into
| The pre-migrated body delimiter expressions could be prefixed with a \n expression for newline, which limited the number of matches to the number of lines in the email, this reduced regexp matching for large emails from billions to a few K (impact of this was processing time). As part of the migration, each historic CSV regexp value was evaluated, and if it started with a \n, had it removed. The reason for this is that ALL Body Delimiters are now prefixed the \n at evaluation time, ensuring that the evaluations are as safe and optimal as possible as well as minimizing the repetitive nature during entry. |
Profile Imports
Old Profiles can be imported into 2.7.3, which will also migrate Body Delimiters from the Profile level to the Default Project Mapping.
Project Mappings
JEMH configuration is being migrated to project-scoped Project Mappings that permit customization within a Profile. There is a Default Project Mapping, which contains no rules, and is used when no other Project Mapping rule matched. The Default Project Mapping can have Cleanup and Delimiter expressions defined that are used by any other Project Mapping as well as having their own.
Type | Subject Cleanup | Body Cleanup | Body Delimiter | Aggregates |
|---|---|---|---|---|
Profile |
|
|
| n/a |
Default Project Mapping |
|
|
| From Profile |
Mapped Project Mapping X |
|
|
| From Default |
Mapped Project Mapping Y |
|
|
| From Default |
Regex 101
Remember that symbols mean something, the dot character ( . ) means match on any character. The star character ( * ) means match on any number of the previous characters. Ranges can be used, eg \[0-9]* means any length of numbers, \[A-Z]+ means 1 or more ALPHA chars, \[0-9A-Za-z]+ means 1 or more ALPHANUM chars. In subjects, there is one line, in body, . matches ALL (full content).
Cleanup Expressions
Maybe its a word, or an expression, that you want removed prior to issue creation, whether in the subject or the body.
Body Delimiters
Body Expressions are required to match the line of text that prefixes 'replied to' content. This content varies depending on the email client used and the locale of the client user. Effectively it is just text so we must match it as closely as possible. As mentioned above ALL delimiter expressions are evaluated with a \n prefixing them to minimize the number of matches. This also works at the start of the email content as \n is dynamically injected for that case, and removed after. Its better to range match on expected text than take the 'lazy' .* route, bad regexps that overuse .* can cause A LOT of possible match evaluations by the Regexp Engine. If your Jira stops processing mail, one possible causes is an overuse of .*, the Regexp Engine is busy, it could take a few hours, days or longer to complete owing to the combination of Regexp and email size.
Dynamic Evaluation walk-through
Based on the following Test Case (you can paste it as a new JEMH Test Case), we will show how cleanups and delimiters can be used.
You may need to change the email to: address to match you Profile > Email > catchEmail expected address, and possible update the From: address to match a Jira user!
MIME-Version: 1.0 Received: by 10.223.112.12 with HTTP; Sat, 18 Jun 2011 22:42:26 -0700 (PDT) Date: Sun, 19 Jun 2011 17:42:26 +1200 Message-ID: <BANLkTinB1mfSh+GwOXGNWoL4SyDvOpdBoQ@mail.gmail.com> Subject: This is a starting email template, ABC update DEF as required From: "Andy Brook" <andy@localhost> To: changeme@thiswontwork.com Content-Type: text/plain; charset=UTF-8 some text GHI hello'world On 5 July 2018 at 06:48, Some bodys name <some.body@some.com> wrote: blah blah blah
Create the test case above, and select the Profile to use. This association means that the Test Case can be picked for self-text in the next section:
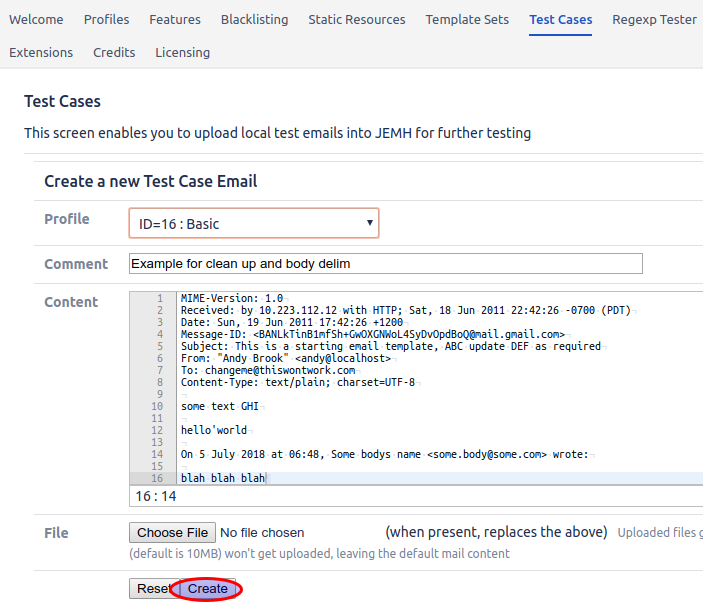
Evaluate the test case with no extra setup
from the Default Project Mapping within the Profile picked in the last step, pick the just saved Test case from the Project Mapping > Pre-Processing > Dynamic Evaluation section, set for Comment processing, you'll see as soon as a Test Case is picked, its automatically evaluated with Output text shown. Its possible from that screen to also quickly see for both Subject and Body, the Input text as well as a summary of what Regexp Rules were executed:
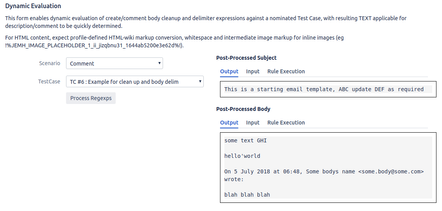
Setting the Profile Default Project Mapping Cleanups
With the Test Case set, access the Pre-Processing tab shown below, and click Add in the Subject section:

A new entry will be dynamically injected, but will not actually be saved - in fact no changes at all will be made until the page is submitted. Set the value to ABC, matching a part of the subject of the Test Case:

Now, as soon as you move out of that text field (eg use TAB) the changes are dynamically evaluated and the result shown, see how ABC is now missing.

We repeat this with a Body Cleanup

And after tabbing out we can see the result:

Next up we add a Body Delimiter Expression, the following will be used as an example, we don't have to match the entire line, just the start (of course, the less you match, the more its 'possible' to match actual body content that should not be clipped):
NOTE: The default for Body Delimiters is to apply on Create as well as Comment:
On [0-9]+ (January|February|March|April|May|June|July|August|September|October|November|December) 20[0-9]{2} at [0-9]{2}:[0-9]{2}
After tabbing out we can see the content was clipped.

For final proof, save the form to persist changes:

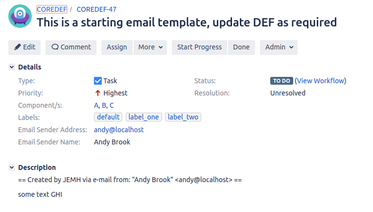
Navigate to the TestCase view, and Run the Test Case against the Profile:

Accessing the related NEW issue, you'll see that the issue summary has the ABC value "Cleaned Up", the Body value hello'world value "Cleaned Up" and the body 'reply to' content clipped:
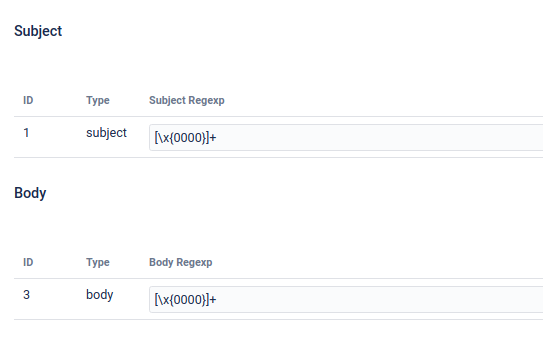
Removing ‘Null’ characters
Null characters can cause email processing to fail if the database used does not support Null characters. Jira will attempt to save the character and return an error, such as:
We can't create this issue for you right now, it could be due to unsupported content you've entered into one or more of the issue fields.
ERROR: invalid byte sequence for encoding "UTF8": 0x00
The following Regexp will identify a ‘null’ character for removal in a Subject or Body Cleanup, allowing emails to be processed.
[\x{0000}]+