Again, so soon?
Yes, we did only just revise capacity at the end of April, but we were asked some interesting questions about extremely large capacities (up to 1 million messages/month) and this is the result.
So what changed?
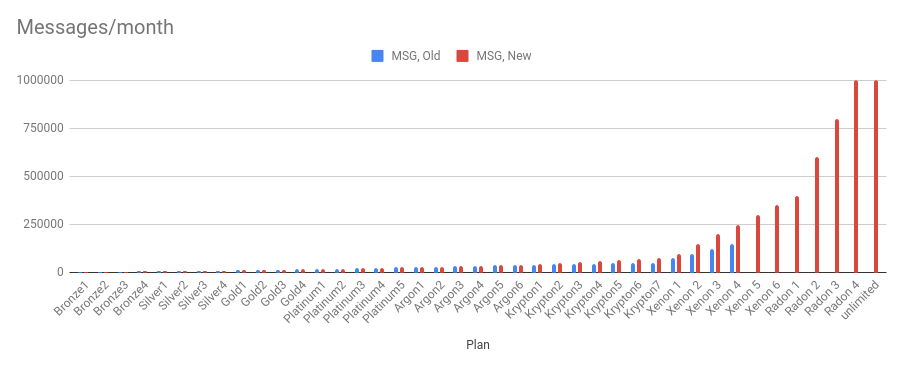
Plan tiers added
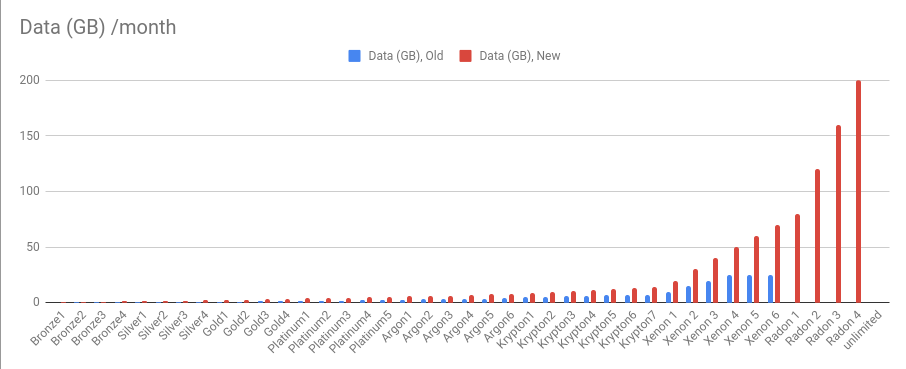
We added extra tiers to Krypton and Xenon, as well as a new Radon plan to for up to 1,000,000 messages per month and 200GB of data per month. An unlimited plan has been added for illustration purposes only.
Data limits increased
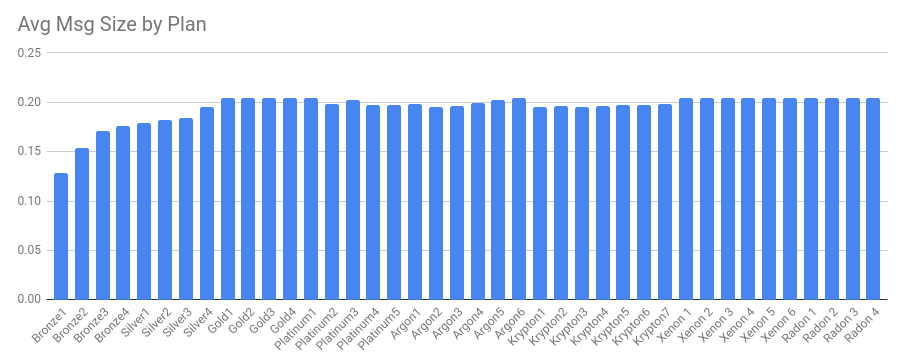
Data allowances have been reviewed, to align more consistently with message limits at each tier. The end result is that data limits have been doubled for most tiers. From Gold 1 and up, this equates to an average of 0.2 MB per message. We expect any future changes to be tied to this ratio to deliver a fair and linearly applied change.
Plan allocations will apply on 1st June 2021.
Costs
We’ve set a flat per-user pricing of a flat $0.5/user for instances between 251 and 10,000 users. This results in a cost reduction for 251-1000 user tiers, and an increase above.
Changes are effective immediately - customers on annual plans will see no change for the current billing cycle.
Charts
Data as a ratio to Messages by plan
Messages/month
DATA/month
Plan Table
1MiB = 1,000 kB, 1GiB = 1,000MiB.
Users | Plan | Messages (old) | Messages (new) | Data (GB - old) | Data (GiB - new) |
|---|---|---|---|---|---|
1-10 | Bronze1 | 4000 | 4000 | 0.25 | 0.5 |
11-15 | Bronze2 | 5000 | 5000 | 0.35 | 0.75 |
16-25 | Bronze3 | 6000 | 6000 | 0.45 | 1 |
26-50 | Bronze4 | 7000 | 7000 | 0.50 | 1.2 |
51-100 | Silver1 | 8000 | 8000 | 0.56 | 1.4 |
101-200 | Silver2 | 9000 | 9000 | 0.63 | 1.6 |
201-300 | Silver3 | 10000 | 10000 | 0.75 | 1.8 |
301-400 | Silver4 | 11000 | 11000 | 0.88 | 2.1 |
401-500 | Gold1 | 12000 | 12000 | 1.0 | 2.4 |
501-600 | Gold2 | 14000 | 14000 | 1.1 | 2.8 |
601-800 | Gold3 | 16000 | 16000 | 1.3 | 3.2 |
801-1000 | Gold4 | 18000 | 18000 | 1.4 | 3.6 |
1001-1200 | Platinum1 | 20000 | 20000 | 1.5 | 4 |
1201-1400 | Platinum2 | 22000 | 22000 | 1.6 | 4.25 |
1401-1600 | Platinum3 | 24000 | 24000 | 1.9 | 4.75 |
1601-1800 | Platinum4 | 26000 | 26000 | 2.1 | 5 |
1801-2000 | Platinum5 | 28000 | 28000 | 2.4 | 5.4 |
2001-2500 | Argon1 | 30000 | 30000 | 2.8 | 5.8 |
2501-3000 | Argon2 | 32000 | 32000 | 3.0 | 6.1 |
3001-3500 | Argon3 | 34000 | 34000 | 3.3 | 6.5 |
3501-4000 | Argon4 | 36000 | 36000 | 3.5 | 7 |
4001-4500 | Argon5 | 38000 | 38000 | 3.8 | 7.5 |
4501-5000 | Argon6 | 40000 | 40000 | 4.0 | 8 |
5001-6000 | Krypton1 | 42000 | 45000 | 5.0 | 8.6 |
6001-7000 | Krypton2 | 44000 | 50000 | 5.5 | 9.6 |
7001-8000 | Krypton3 | 46000 | 55000 | 6.0 | 10.5 |
8001-9000 | Krypton4 | 48000 | 60000 | 6.5 | 11.5 |
9001-10000 | Krypton5 | 50000 | 65000 | 7.0 | 12.5 |
Krypton6 | 50000 | 70000 | 7.0 | 13.5 | |
Krypton7 | 50000 | 75000 | 7.0 | 14.5 | |
Xenon 1 | 75000 | 100000 | 10.0 | 20 | |
Xenon 2 | 100000 | 150000 | 15.0 | 30 | |
Xenon 3 | 125000 | 200000 | 20.0 | 40 | |
Xenon 4 | 150000 | 250000 | 24.9 | 50 | |
Xenon 5 | 300000 | 24.9 | 60 | ||
Xenon 6 | 350000 | 24.9 | 70 | ||
Radon 1 | 400000 | 80 | |||
Radon 2 | 600000 | 120 | |||
Radon 3 | 800000 | 160 | |||
Radon 4 | 1000000 | 200 | |||
Unlimited | Unlimited | Unlimited |
What problem are we solving
We noticed recently that massive volumes of webhooks (JSON payloads from your Jira instances in response to changes you make to issues) could overwhelm JEMHC causing UI non-availability and general instability. The root cause was determined as a direct correlation between incoming webhook and processing requiring a database connection.
What we did
The change we have gone live with today decouples inbound webhook receipt from actual processing and ensures that app performance remains consistent even when we receive massive ‘bulk change’ webhook posts from clients.
Impact
Customers will not notice anything different.
Worst case scenario
As we group incoming webhooks by host, its possible that a host that generates a few thousand webhooks ‘first’ will delay processing of another host in the same group, this is because hooks are processed in a FIFO (first in first out) manner to retain timeline consistency. Hooks will be consumed as fast as possible!
After a call with a partner today, I wanted to write about JEMHC capacity Plans and support for Large Scale Customers and why we do the things we do. More background is on the Licensing page.
Why limit at all
JEMHC is a shared service, capacity Plans were built from inception to make the Customer accountable for the data processed through their configuration, to:
Prevent broken configurations (e.g. mail loops) loading the system and degrading performance for all customers by capping the volume (msg + data) that they can process per month
To incentivise the customer to correct configuration to ensure mail retrieved is actually useful, rather than just feeding us unlimited content, for some small subset to be acted on
How we determine limits
Plan capacities are not fixed and are reviewed ongoing, the capacities set allow for the vast majority of customers, when considered by their active subscription user count, to process and send mail at no extra cost. There are always outlier top-volume customers in every Plan tier, for them additional capacity is offered through Data Packs (short term, more expensive) and Plan Upgrades (12 month term commitment, cheaper).
Subscription costs
JEMHC like all Atlassian cloud apps is paid per-user, there is a tiered pricing structure that is applied monthly, so regardless of whether a customer has bought a ‘premium’ subscription (e.g. 500), apps like JEMHC do not see that and only charge for active users that also happens to drive Plan Allocation, so the Plan may be lower than expected.
As customers active subscription users increase, they already get a higher Plan, so in theory, and from our records, we can see most customers are fine. JEMHC is designed to scale, we welcome larger customers with open arms.
Why purchasing Data Packs and Plan Upgrades is not in Marketplace
We’ve asked and lobbied Atlassian, to no avail. There are simply not enough ‘volume’ sensitive apps for Atlassian to take note of this case, so JEMHC is in itself unique. We do it ourselves because we have to, because Plan Limits (and dealing with the consequence of customers hitting them) is integral to being able to offer JEMHC to customers.
Cloud: It has to be a mutual fit
Where JEMHC differs from most cloud apps is the IO load it takes on, it simply is not a case of a simple storage bucket. The typical point of contention typically comes with ‘relatively low' subscription users and ‘relatively high’ data volumes. For our part whilst we would hope to attract larger customers, we cannot do so where it doesn't work for us, eg:
Customer has 115 active users, is allocated the Silver2 Plan of 9K msgs and 640MB pcm. Customer monthly data demand is for 125Kmsgs (14x allocated plan) and unknown data volumes pcm for the same cost ($287.5 pcm)
As you’d expect, JEMHC can scale up to meet demand but that has obvious costs. In the above example, on a cost basis, it is simply not viable for us to support customers high data demand (and provide support) for ‘relatively low’ subscription users. If customers do not want to pay more, we have no real way to do more and JEMHC is regretfully not going to work out in that case………
The future:
We will continue to review customer usage and revise plan capacities over time, as we have increased both Data and Message volume in the last few months, there won’t be changes for a while.
For customers that require much higher volumes than Krypton, we added Xenon “Large Volume Messaging” Plan tiers covering capacities up to 150Kmsg and 25GB pcm for discussion, as yet unpriced.
(content here was initially created as a page…)
Summary
Yesterday, from around 1430 UTC the JEMHC application started to experience performance issues causing general non availability of the UI and delays in processing inbound mail and generating outbound mail. Normal service was resumed at around 23:30 UTC.
What happened
Yesterday we had an extended outage resulting the delay of mail being processed in and sent out, the root cause of this was our application not limiting the concurrent handling of incoming webhooks from Jira instances for retry (see Retry policy). The consequence was exhaustion of database connections resulting in general lockup feedback back from the db into other areas of the app, triggering health check fail and node reboot cycles. The UI was impacted because webhooks are currently processed in the same nodes.
Mitigation
Contributing factors were also the the recent onboarding of a few very large volume customers, meaning there was less free processing headroom than before. To improve resilience under load we have doubled the processing capacity of the JEMHC database to handle the doubling of DB load over the last year.
Remediation
In the next few days we will update our inbound webhook handler to prevent similar overload scenarios, in the longer term we plan to decouple webhook processing from the UI entirely.
Sorry for any inconvenience caused.